Работает, если у вас есть сотня клиентов
Если ABCDX-сегментация требует хотя бы тысячи b2c клиентов, то сегментация Шона Эллиса работает на сотнях.
Шон Эллис [Sean Ellis, основатель сообщества growthhackers.com, делал команды роста в Dropbox, участвовал в выводе на IPO LogMeIn и uproar.com] предположил, что если опросить клиентов продукта у которого есть Product/Market Fit, то можно увидеть корреляцию с пороговым значением % клиентов, которые говорят, что будут сильно разочарованы, если продукт исчезнет.
Хилтен Шах [Hilten Shah, сооснователь KISSmetrics, CrazyEgg] провёл опрос по пользователям Slack'а и увидел, что 50% клиентов Slack будут сильно разочарованы, если продут исчезнет.
Рахул Вохра [Rahul Vohra, основатель Superhuman] имея пару тысяч бета-клиентов, провёл опрос и увидел, что всего 22% его клиентов будут разочарованы, если Superhuman исчезнет
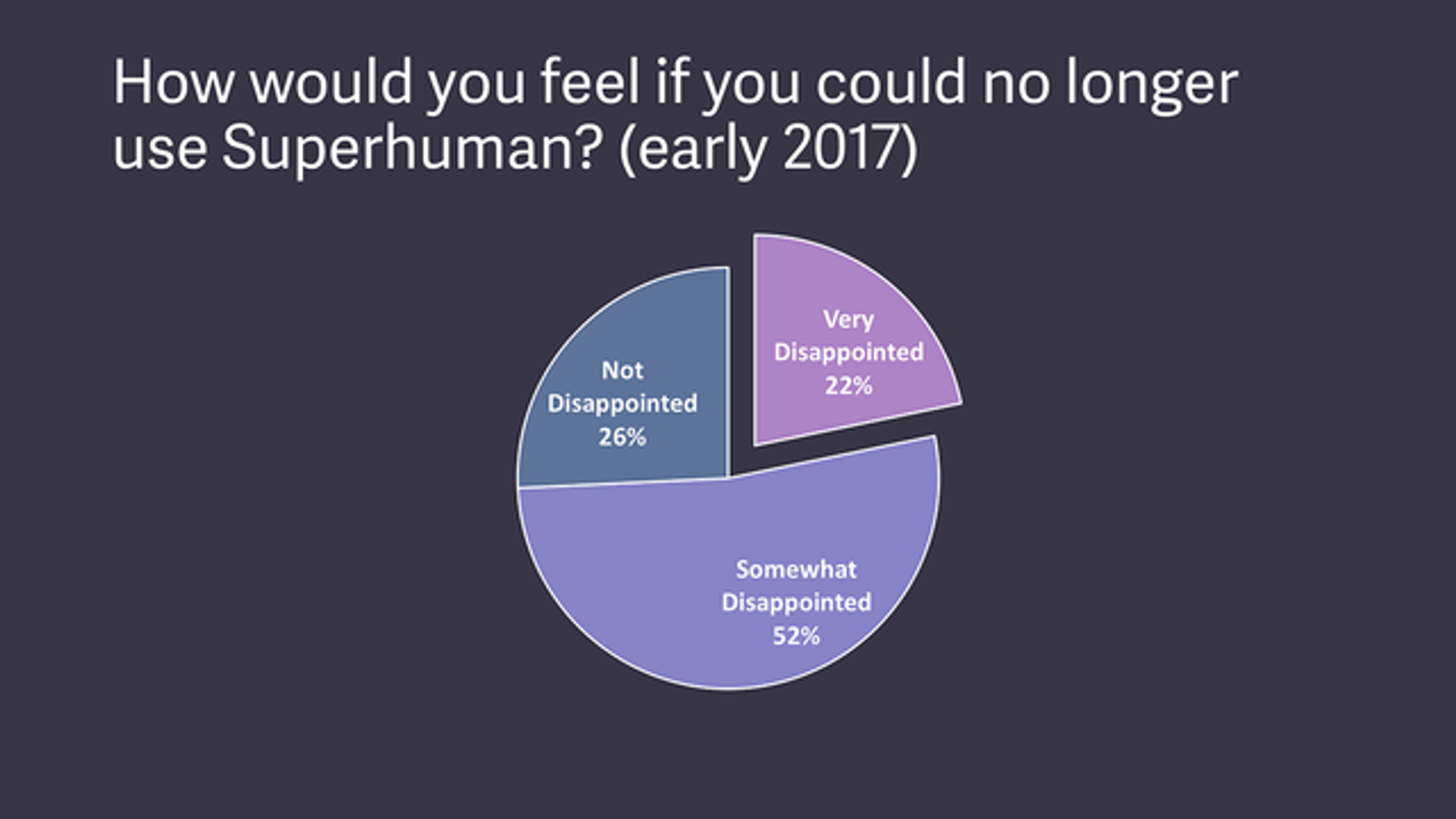
После этого он посмотрел, какие роли встречаются чаще среди тех, кто будут сильно разочарованы. И чаще встречались четыре роли: основатели компаний, руководители, топ-менеджеры и биздевы.

Провёл повторный опрос среди этих четырёх ролей и увидел, что среди этого сегмента у него уже есть движение к Product/Market Fit'у
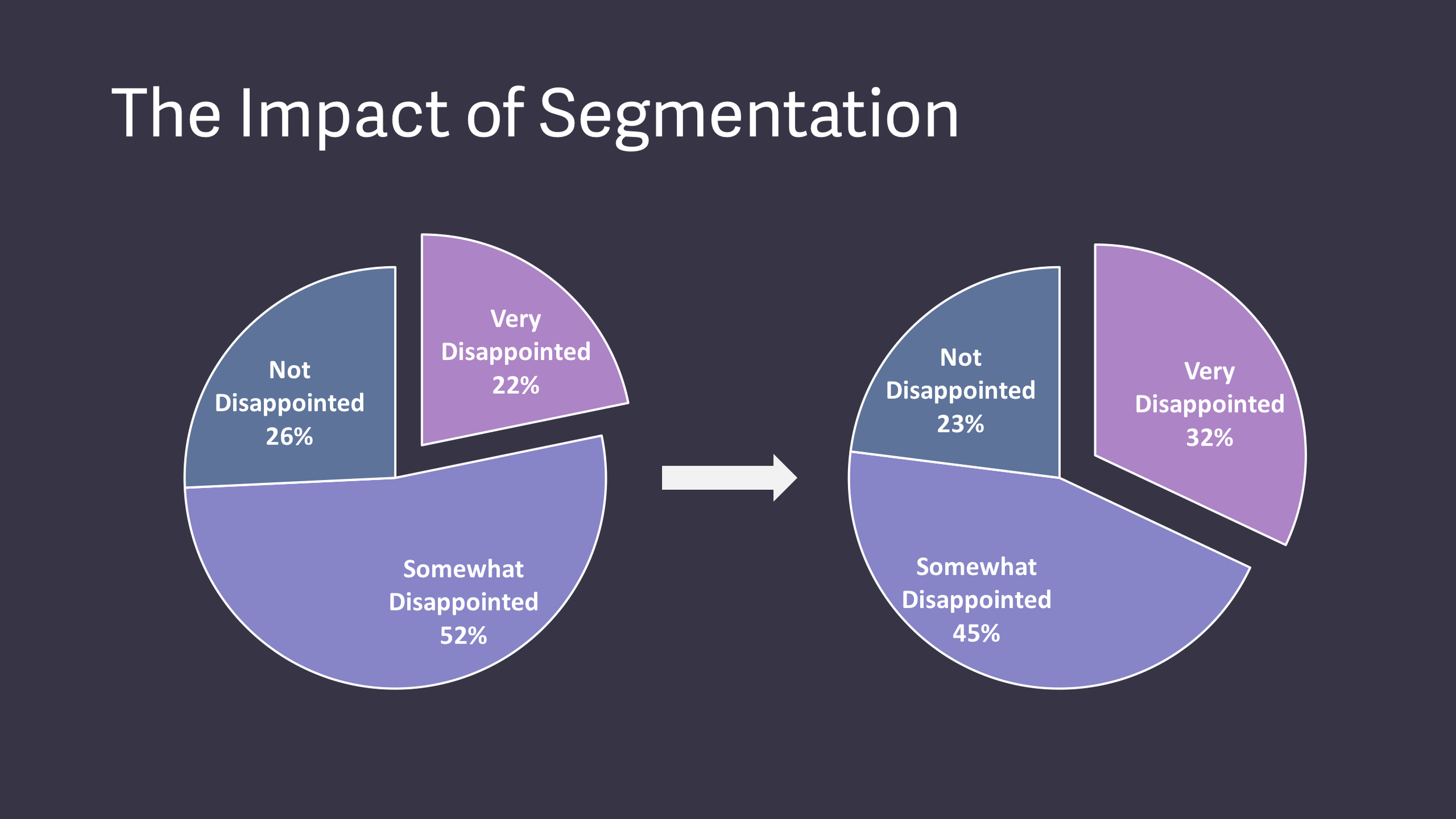
Затем, он спросил у тех, кто отвечал, что они будут умеренно разочарованы, чего им не хватает в Superhuman и по их запросам в течение года пилил продукт. И за год вышел до 58% тех, кто будут сильно разочарованы
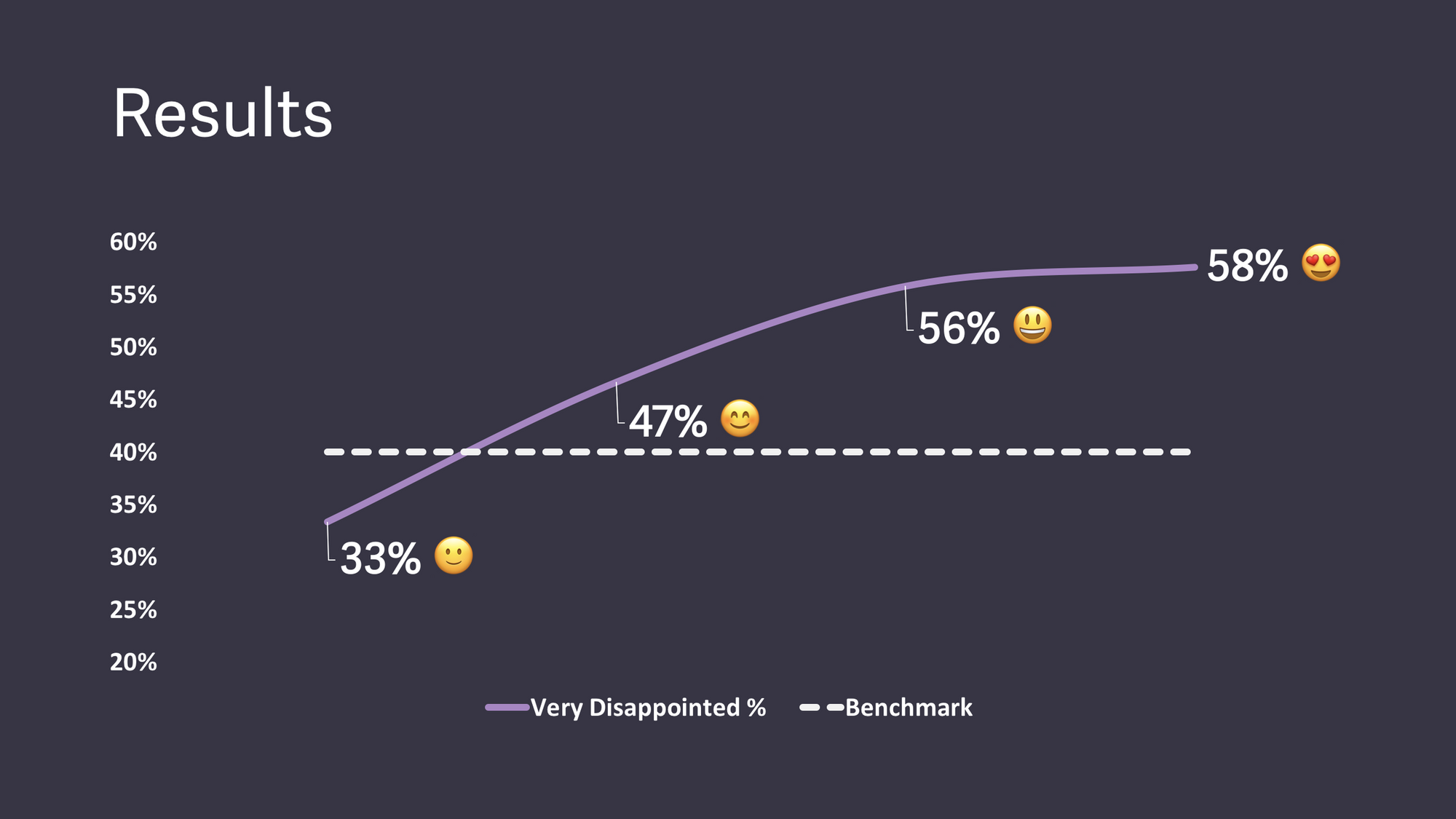
Рахул не повторял опросы на одних и тех же клиентах. Когда вы будете проектировать похожее исследование среди клиентов своего продукта—не делайте первый опрос на всю выборку, чтобы в повторные опросы не попадали клиенты из выборки первого опроса.
Всё нравится, как провести опрос?
Олег Якубенков запилил вместе с Шоном Эллисом специальный инструмент для проведения этого опроса: https://pmfsurvey.com
Нюансы
Помните, что на небольших выборках большое значение имеет погрешность измерения при экстраполяции на всю выборку. Если из 200 человек 80 ответили, что будут сильно разочарованы, при экстраполяции на всю выборку доверительный интервал будет +/- 5% при точности 90%, то есть все, кого выборка представляет будут лежать в интервале от 35% до 45%